Renderer 更新 -> 乱序 Diff
在上一章中,我们实现了双端 diff 算法,能够高效处理头部和尾部的节点变化。但在实际应用中,还会遇到更复杂的场景——节点的顺序发生了变化,或者中间插入、删除了节点。这种情况下,双端对比无法完全处理,需要更智能的乱序 diff 算法。
乱序场景的挑战
什么是乱序 diff
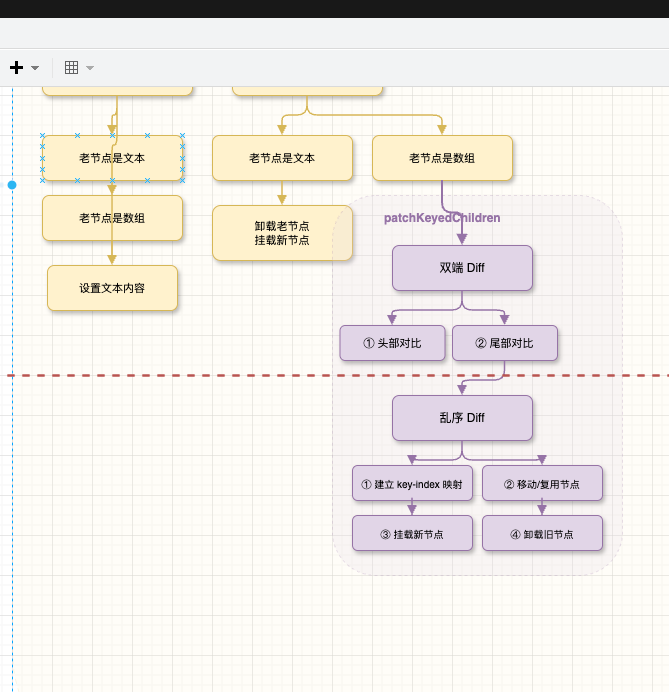
当双端对比完成后,如果中间还有未处理的节点,且这些节点的顺序发生了变化,就需要进入乱序 diff 流程。来看一个典型的场景:
import { h, render } from '../dist/vue.esm.js'
const vNode = h('div', [
h('p', { key: 'a', style: { color: 'blue' } }, 'a'),
h('p', { key: 'b', style: { color: 'blue' } }, 'b'),
h('p', { key: 'c', style: { color: 'blue' } }, 'c'),
h('p', { key: 'd', style: { color: 'blue' } }, 'd'),
h('p', { key: 'e', style: { color: 'blue' } }, 'e')
])
const vNode2 = h('div', [
h('p', { key: 'a', style: { color: 'red' } }, 'a'),
h('p', { key: 'c', style: { color: 'red' } }, 'c'),
h('p', { key: 'd', style: { color: 'red' } }, 'd'),
h('p', { key: 'b', style: { color: 'red' } }, 'b'),
h('p', { key: 'e', style: { color: 'red' } }, 'e')
])
render(vNode, app)
setTimeout(() => {
render(vNode2, app)
}, 1000)
变化分析:
- 旧节点 (c1):
[a, b, c, d, e] - 新节点 (c2):
[a, c, d, b, e] - 节点
b从索引 1 移动到了索引 3
双端 diff 的局限性
经过双端对比后,我们会得到:
- 头部对比:
a === a,i前进到 1 - 尾部对比:
e === e,e1和e2后退到 3 - 结果:
i = 1, e1 = 3, e2 = 3
此时,i <= e1 且 i <= e2,说明中间还有节点 [b, c, d] 和 [c, d, b] 需要处理。虽然这些节点的 key 都存在,但顺序发生了变化。我们不能简单地卸载重建,而应该复用这些节点并调整它们的位置。
乱序 Diff 算法实现
核心思路
乱序 diff 的核心策略分为两步:
- 找出可复用的节点:通过
key建立新旧节点的映射关系,找出哪些节点可以复用,哪些需要卸载 - 调整节点顺序:将可复用的节点移动到正确的位置,并挂载新增的节点
第一步:建立索引映射
首先,我们需要建立新节点的 key 到索引的映射关系,这样就能快速判断旧节点是否在新节点中存在。
function patchKeyedChildren(c1, c2, container) {
// ... 双端 diff 代码
if (i > e1) {
// 挂载新节点
}
else if (i > e2) {
// 卸载旧节点
}
else {
// 进入乱序 diff 流程
// 记录未处理节点的起始位置
const s1 = i // 旧节点数组中的起始索引
const s2 = i // 新节点数组中的起始索引
/**
* 建立新节点的 key -> index 映射
*
* 以示例场景为例:
* c1: [a, (b, c, d), e] -> s1 = 1, e1 = 3
* c2: [a, (c, d, b), e] -> s2 = 1, e2 = 3
*
* 建立的映射关系:
* keyToNewIndexMap = {
* c: 1, // c 在新数组中的索引是 1
* d: 2, // d 在新数组中的索引是 2
* b: 3 // b 在新数组中的索引是 3
* }
*/
const keyToNewIndexMap = new Map()
// 遍历新节点的未处理区域,建立映射
for (let j = s2; j <= e2; j++) {
const n2 = c2[j]
keyToNewIndexMap.set(n2.key, j)
}
/**
* 遍历旧节点,判断是否可复用
*
* 对于每个旧节点:
* - 如果在新节点中找到相同的 key,说明可以复用,进行 patch 更新
* - 如果在新节点中找不到,说明该节点被删除,需要卸载
*/
for (let j = s1; j <= e1; j++) {
const n1 = c1[j]
const newIndex = keyToNewIndexMap.get(n1.key)
if (newIndex !== undefined) {
// 找到了对应的新节点,进行更新
patch(n1, c2[newIndex], container)
}
else {
// 在新节点中找不到,卸载这个旧节点
unmount(n1)
}
}
}
}
关键要点:
keyToNewIndexMap存储的是新节点中未处理区域的映射关系- 通过这个映射,可以快速查找旧节点是否存在于新节点中
- 此时只完成了节点的更新(
patch),但节点的DOM顺序还是错误的
第二步:调整节点顺序
完成节点的更新后,我们需要将它们移动到正确的位置。这一步采用倒序插入的策略,从后往前遍历新节点数组,将每个节点插入到正确的位置。
/**
* 倒序遍历新节点的未处理区域
*
* 为什么要倒序?
* - 因为我们需要一个稳定的参照点(anchor)来确定插入位置
* - 从后往前处理,每次插入时,后面的节点位置已经是正确的
* - 这样可以使用 c2[j + 1] 作为 anchor,保证插入位置准确
*/
for (let j = e2; j >= s2; j--) {
const n2 = c2[j]
/**
* 确定锚点位置
* - anchor 是当前节点应该插入到哪个节点之前
* - c2[j + 1] 是新数组中的下一个节点(已经处理过,位置正确)
* - 如果 j + 1 超出数组范围,说明是最后一个节点,anchor 为 null(追加到末尾)
*/
const anchor = c2[j + 1]?.el || null
if (n2.el) {
// 节点已存在(在第一步中被 patch 过),只需要移动位置
hostInsert(n2.el, container, anchor)
}
else {
// 节点不存在(新增节点),需要挂载
patch(null, n2, container, anchor)
}
}
倒序插入的原理:
以示例场景为例,说明倒序插入的过程:
- 新节点:
[a, (c, d, b), e],未处理区域:s2 = 1, e2 = 3 - 倒序遍历顺序:
j = 3 → 2 → 1
| 轮次 | j | 当前节点 | anchor (c2j+1) | 操作 |
|---|---|---|---|---|
| 1 | 3 | b | e.el | 将 b 插入到 e 之前 |
| 2 | 2 | d | b.el | 将 d 插入到 b 之前 |
| 3 | 1 | c | d.el | 将 c 插入到 d 之前 |
通过这个过程,所有节点都被移动到了正确的位置:[a, c, d, b, e]。
关键点
1. 为什么需要 key
key 是节点复用的关键标识。没有 key,我们就无法判断新旧节点的对应关系,只能通过位置来比较:
- 没有 key:只能按索引对比,
c1[0]vsc2[0],c1[1]vsc2[1]... - 有 key:可以通过
key建立映射,准确找到节点的对应关系
在乱序场景中,key 让我们能够识别出"节点 b 只是移动了位置,而不是被删除后又新增",从而实现节点的复用和移动,而不是销毁重建。
2. 为什么采用倒序插入
倒序插入的核心优势是:后面的节点位置已经确定,可以作为稳定的参照点(anchor)。
如果采用正序插入,会遇到问题:
- 正序插入时,后面的节点位置还未确定
- 无法准确找到
anchor来确定插入位置 - 可能导致节点插入位置错误
倒序插入保证了:
- 每次处理节点时,
c2[j + 1]的位置已经正确 - 可以安全地使用
c2[j + 1].el作为anchor - 插入位置准确,不会出现错位
3. 新增节点的处理
在倒序插入时,我们通过 n2.el 的值来判断节点的状态:
- n2.el 存在:说明这个节点在第一步中被
patch过,已经有对应的DOM元素,只需要移动位置 - n2.el 不存在:说明这是一个新增节点,在旧节点中不存在,需要执行
patch(null, n2, ...)进行挂载
这个判断机制让我们能够统一处理节点的移动和新增,简化了代码逻辑。
4. 算法的时间复杂度
乱序 diff 算法的时间复杂度分析:
- 建立映射:遍历新节点未处理区域 →
O(n) - 查找和更新:遍历旧节点未处理区域,每次查找
Map的时间是O(1)→O(n) - 调整顺序:倒序遍历新节点未处理区域 →
O(n)
总体时间复杂度:O(n),其中 n 是未处理区域的节点数量。相比于简单的卸载重建(也是 O(n)),虽然时间复杂度相同,但乱序 diff 能够最大化地复用 DOM 节点,避免了大量的创建和销毁操作,实际性能提升显著。
完整的 patchKeyedChildren 实现
将双端 diff 和乱序 diff 结合起来,完整的实现如下:
function patchKeyedChildren(c1, c2, container) {
let i = 0
let e1 = c1.length - 1
let e2 = c2.length - 1
// 1. 头部对比
while (i <= e1 && i <= e2) {
const n1 = c1[i]
const n2 = c2[i]
if (isSameVNodeType(n1, n2)) {
patch(n1, n2, container)
}
else {
break
}
i++
}
// 2. 尾部对比
while (i <= e1 && i <= e2) {
const n1 = c1[e1]
const n2 = c2[e2]
if (isSameVNodeType(n1, n2)) {
patch(n1, n2, container)
}
else {
break
}
e1--
e2--
}
// 3. 处理对比结果
if (i > e1) {
// 挂载新节点
const nextPos = e2 + 1
const anchor = nextPos < c2.length ? c2[nextPos].el : null
while (i <= e2) {
patch(null, c2[i], container, anchor)
i++
}
}
else if (i > e2) {
// 卸载旧节点
while (i <= e1) {
unmount(c1[i])
i++
}
}
else {
// 4. 乱序 diff
const s1 = i
const s2 = i
// 建立新节点的 key 映射
const keyToNewIndexMap = new Map()
for (let j = s2; j <= e2; j++) {
const n2 = c2[j]
keyToNewIndexMap.set(n2.key, j)
}
// 遍历旧节点,更新或卸载
for (let j = s1; j <= e1; j++) {
const n1 = c1[j]
const newIndex = keyToNewIndexMap.get(n1.key)
if (newIndex !== undefined) {
patch(n1, c2[newIndex], container)
}
else {
unmount(n1)
}
}
// 倒序调整节点位置
for (let j = e2; j >= s2; j--) {
const n2 = c2[j]
const anchor = c2[j + 1]?.el || null
if (n2.el) {
hostInsert(n2.el, container, anchor)
}
else {
patch(null, n2, container, anchor)
}
}
}
}
总结
通过本章的学习,我们实现了乱序 diff 算法,这是 Vue 渲染器中最复杂也最强大的优化之一。让我们回顾一下核心内容:
- 乱序 diff 的应用场景:
- 双端对比无法完全处理的情况
- 中间节点顺序发生变化
- 包含节点的新增、删除和移动
- 算法的核心策略:
- 第一步:建立
key到索引的映射,找出可复用的节点并更新 - 第二步:倒序遍历新节点,调整节点位置并挂载新增节点
- 通过
Map实现O(1)的查找效率
- 第一步:建立
- key 的重要性:
- 是节点复用的唯一标识
- 让算法能够准确识别节点的对应关系
- 避免不必要的销毁和重建,提升性能
- 倒序插入的原理:
- 保证每次插入时,后面的节点位置已经正确
- 可以使用
c2[j + 1].el作为稳定的anchor - 确保插入位置的准确性
- 算法的性能特点:
- 时间复杂度:
O(n) - 空间复杂度:
O(n)(存储keyToNewIndexMap) - 最大化节点复用,减少
DOM操作 - 相比简单的卸载重建,实际性能提升显著
- 时间复杂度:
- 与双端 diff 的配合:
- 双端
diff快速处理头尾变化 - 乱序
diff处理中间的复杂情况 - 两者结合,覆盖所有列表更新场景
- 双端
至此,我们已经实现了一个功能完整的 diff 算法,能够高效处理各种列表更新场景。这套算法是 Vue 渲染器性能优化的核心,也是前端框架中最经典的算法之一。